软件总体结构
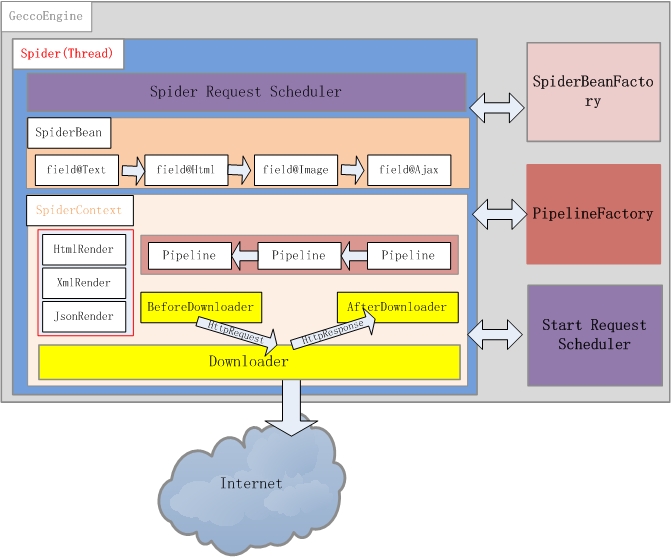
基本构件介绍
GeccoEngine
GeccoEngine是爬虫引擎,每个爬虫引擎最好是一个独立进程,在分布式爬虫场景下,建议每台爬虫服务器(物理机或者虚机)运行一个GeccoEngine。爬虫引擎包括主要Scheduler、Downloader、Spider、SpiderBeanFactory、PipelineFactory5个主要模块。
Scheduler
通常爬虫需要一个有效管理下载地址的角色,Scheduler负责下载地址的管理。gecco对初始地址的管理使用StartScheduler,StartScheduler内部采用一个阻塞的FIFO的队列。初始地址通常会派生出很多其他待抓取的地址,派生出来的其他地址采用SpiderScheduler进行管理,SpiderScheduler内部采用线程安全的非阻塞FIFO队列。这种设计使的gecco对初始地址采用了深度遍历的策略,即一个线程抓取完一个初始地址后才会去抓取另外一个初始地址;对初始地址派生出来的地址,采用广度优先策略。
Downloader
Downloader负责从Scheduler中获取需要下载的请求,gecco默认采用httpclient4.x作为下载引擎。通过实现Downloader接口可以自定义自己的下载引擎。你也可以对每个请求定义BeforeDownload和AfterDownload,实现不同的请求下载的个性需求。
SpiderBeanFactory
Gecco将下载下来的内容渲染为SpiderBean,所有爬虫渲染的JavaBean都统一继承SpiderBean,SpiderBean又分为HtmlBean和JsonBean分别对应html页面的渲染和json数据的渲染。SpiderBeanFactroy会根据请求的url地址,匹配相应的SpiderBean,同时生成该SpiderBean的上下文SpiderBeanContext。上下文SpiderBeanContext会告知这个SpiderBean采用什么渲染器,采用那个下载器,渲染完成后采用哪些pipeline处理等相关上下文信息。
PipelineFactory
pipeline是SpiderBean渲染完成的后续业务处理单元,PipelineFactory是pipeline的工厂类,负责pipeline实例化。通过扩展PipelineFactory就可以实现和Spring等业务处理框架的整合。
Spider
Gecco框架最核心的类应该是Spider线程,一个爬虫引擎可以同时运行多个Spider线程。Spider描绘了这个框架运行的基本骨架,先从Scheduler获取请求,再通过SpiderBeanFactory匹配SpiderBeanClass,再通过SpiderBeanClass找到SpiderBean的上下文,下载网页并对SpiderBean做渲染,将渲染后的SpiderBean交个pipeline处理。